# ========================================# Comprehensive Introduction to the Tidyverse Companion Script# ========================================# The Tidyverse is a collection of R packages designed to make data science faster, easier, and more fun.# It provides a consistent and intuitive framework for data manipulation, visualization, and analysis.# ----------------------------------------# Installing and Loading Tidyverse# ----------------------------------------# Install Tidyverse (you only need to do this once)# Uncomment the line below if you haven't installed Tidyverse yet# install.packages("tidyverse")# Load Tidyverse (do this every time you start a new R session and want to use Tidyverse)library(tidyverse)# ----------------------------------------# Examples of Tidyverse Functions# ----------------------------------------# lets do a quick example (note : BMIs are sort of obsolete and bad science)# Create a sample datasetdata<-data.frame( name =c("Alice", "Bob", "Charlie", "David"), sex =c("F", "M", "M", "M"), age =c(25, 30, 35, 40), height =c(160, 170, 180, 190), weight =c(50, 60, 80, 100))# Display the datahead(data)# 1. filter(): Subset rows based on conditionsdata_filtered<-filter(data, sex=="M")print("Filtered data (males only):")print(data_filtered)# 2. select(): Pick columns by namedata_selected<-select(data_filtered, name, age, height, weight)data_selected<-select(data_filtered, -sex)print("Selected columns:")print(data_selected)# 3. arrange(): Change the order of rowsdata_arranged<-arrange(data_selected, desc(age))print("Arranged data (by age, descending):")print(data_arranged)# 4. mutate(): Add new variablesdata_mutated<-mutate(data_arranged, bmi =weight/(height/100)^2)print("Data with BMI added:")print(data_mutated)# 5. mutate() with case_when(): Add conditional variablesdata_remutated<-mutate(data_mutated, bmi_category =case_when(bmi<18.5~"Underweight",bmi<25~"Normal",bmi<30~"Overweight",TRUE~"Obese"))print("Data with BMI category added:")print(data_remutated)# Multiple Choice Q2: Which Tidyverse function would you use to create a new column in your dataset?# a) select()# b) filter()# c) mutate()# d) arrange()# ----------------------------------------# The Pipe Operator# ----------------------------------------# %>% # |># The pipe operator (|>) allows you to chain operations together in a more readable way.# It takes the output of one function and passes it as the first argument to the next function.# Same operations as above, but using pipesresult_with_pipes<-data|>filter(sex=="M")|>select(-sex)|>arrange(desc(age))|>mutate( bmi =weight/(height/100)^2, bmi_category =case_when(bmi<18.5~"Underweight",bmi<25~"Normal",bmi<30~"Overweight",TRUE~"Obese"))result_with_pipes# Multiple Choice Q3: What does the pipe operator (|>) do in R?# a) It creates a new variable# b) It filters the data# c) It passes the output of one function as the input to the next function# d) It arranges the data in descending order# ----------------------------------------# Key Tidyverse Packages# ----------------------------------------# 1. dplyr: For data manipulation# 2. tidyr: For tidying data# 3. ggplot2: For data visualization# 4. readr: For reading rectangular data# 5. purrr: For functional programming# 6. tibble: For modern data frames# ----------------------------------------# Data Transformation with dplyr# ----------------------------------------# Let's use a real dataset for this examplefish_data<-read.csv("https://raw.githubusercontent.com/laurenkolinger/MES503data/main/week3/s4pt4_fishbiodivCounts_23sites_2014_2015.csv")fish_summary<-fish_data|>filter(year==2015)|>group_by(trophicgroup)|>summarise( avg_count =mean(counts), total_count =sum(counts))|>arrange(desc(total_count))print("Summary of fish data:")print(fish_summary)# Multiple Choice Q5: In the code above, what does the group_by() function do?# a) It filters the data for specific groups# b) It arranges the data by group# c) It creates separate groups for subsequent operations# d) It counts the number of groups in the data# ----------------------------------------# Data Visualization with ggplot2# ----------------------------------------# Basic structure of a ggplot:# ggplot(data = <DATA>) +# <GEOM_FUNCTION>(mapping = aes(<MAPPINGS>))# Create a boxplot of fish counts by trophic groupggplot(fish_data, aes(x =trophicgroup, y =counts))+geom_boxplot()+theme_minimal()+labs(title ="Fish Counts by Trophic Group", x ="Trophic Group", y ="Count")# Multiple Choice Q6: In ggplot2, what does the aes() function do?# a) It adds aesthetic elements like colors and shapes to the plot# b) It specifies the axes of the plot# c) It maps variables in the data to visual properties of the plot# d) It arranges multiple plots in a grid# ----------------------------------------# Practice Script: Lab Assignment 1 in R# ----------------------------------------# Load required librarieslibrary(readxl)library(dplyr)library(ggplot2)library(httr)# Download Excel file from GitHub and read iturl<-"https://github.com/laurenkolinger/MES503data/raw/main/week1/TCRMP-RAPID-Dec2017-Health-intercept.xlsx"temp_file<-tempfile(fileext =".xlsx")GET(url, write_disk(temp_file))dat<-read_excel(temp_file, sheet ="DATA")# Create a summary of the length data for specified specieslength_summary<-dat|>filter(SPP%in%c("AA", "OA", "OFAV", "OFRA", "PA", "SS"))|>group_by(SPP)|>summarise( mean_length =mean(LENGTH), sd_length =sd(LENGTH), SEM_length =sd(LENGTH)/sqrt(length(LENGTH)))# Plot the average length of the specified species with error barsggplot(length_summary, aes(x=SPP, y=mean_length))+geom_bar(stat="identity")+geom_errorbar(aes(ymin =mean_length-SEM_length, ymax =mean_length+SEM_length), width =0.2)+xlab("species")+ylab("length (cm)")+ggtitle("average length of 6 common coral species ± SEM")# Create a summary of the count and percentage of observations for each transect and speciesprev_summary<-dat|>group_by(TRANSECT, SPP)|>summarise(count =n())|>mutate(percentage =(count/sum(count))*100)|>filter(SPP=="MC")print("Prevalence summary:")print(prev_summary)
As you’ve been working with R, you may have noticed that some tasks can become quite complex, requiring multiple steps and creating intermediate variables. This is where the Tidyverse comes in - a collection of R packages designed to make data science faster, easier, and more fun. Let’s dive into this powerful toolkit, starting with one of its most revolutionary features: the pipe operator.
This will load several other packages, including dplyr, ggplot2, and tibble, among many others.
Load Tidyverse
Do this any time you need to use any of thes packages above. This is faster than loading single packages, but also common to see single packages loaded (e.g., library(ggplot2) ).
#either keep all the columns you wantdata_selected<-select(data_filtered, name, age, height, weight)#or remove the column you dont. data_selected<-select(data_filtered, -sex)head(data_selected)
name age height weight
1 Bob 30 170 60
2 Charlie 35 180 80
3 David 40 190 100
lets arrange the data by age in descending order (from oldst to youngest)
The pipe operator |> (or %>% in older R versions) is a key feature of the tidyverse. It allows you to chain operations in a readable way.
The pipe takes the output of one function and passes it as the first argument to the next function.
Imagine you’re in a kitchen, preparing a meal. You need to wash, chop, and cook your ingredients. In traditional R, you might do something like this:
ingredients<-c("carrot", "potato", "onion")washed<-wash(ingredients)chopped<-chop(washed)cooked<-cook(chopped)# another way of putting this:cooked<-cook(chop(wash(ingredients)))
This works, but it’s not very intuitive. You have to read from the inside out, and you’re creating multiple intermediate variables. Now, let’s see how the pipe operator (|> or %>%) changes this:
See how much more readable that is? It’s like a recipe: take the ingredients, then wash them, then chop them, then cook them. The pipe takes the output of one function and feeds it as the input to the next function.
The pipe operator works by taking the output of the expression on its left and passing it as the first argument to the function on its right. It’s as if each function is saying, “Give me what you’ve got so far, and I’ll do my part.”
This approach has several benefits: 1. It makes your code more readable and intuitive. 2. It reduces the need for intermediate variables. 3. It allows you to think about your data in a step-by-step manner.
Pipes vs. Regular Function Calls
Let’s compare pipes to regular function calls using a real data example. We’ll use the mtcars dataset, which is built into R.
The piped version is more concise and reads like a series of steps: “Take mtcars, then arrange by mpg, then filter for 6 cylinders, then select mpg and hp, then mutate to add kpl.”
Also note the syntax (wording) used in the Some examples section above. Same thing.
Key Tidyverse Packages
The Tidyverse includes several packages, each designed for specific tasks:
dplyr: For data manipulation
tidyr: For tidying data
ggplot2: For data visualization
readr: For reading rectangular data
purrr: For functional programming
tibble: For modern data frames
Let’s explore some key functions from dplyr and ggplot2.
Data Transformation with dplyr
dplyr provides a set of verbs for data manipulation:
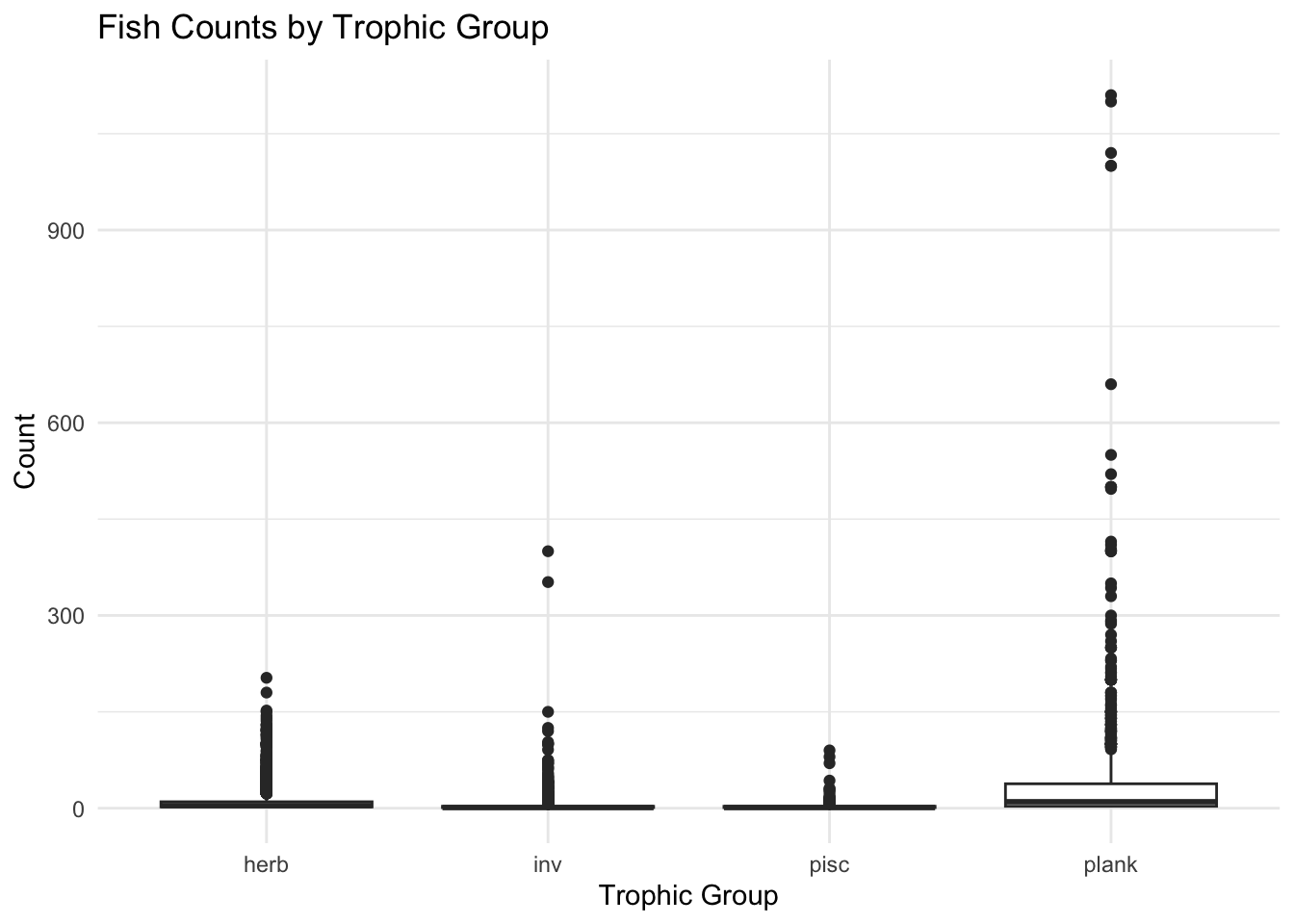
This code filters for 2015 data, groups by trophic group, calculates average and total counts, and arranges the results by total count in descending order.
Data Visualization with ggplot2
ggplot2 is based on the Grammar of Graphics, allowing you to build plots layer by layer. Here’s a basic structure:
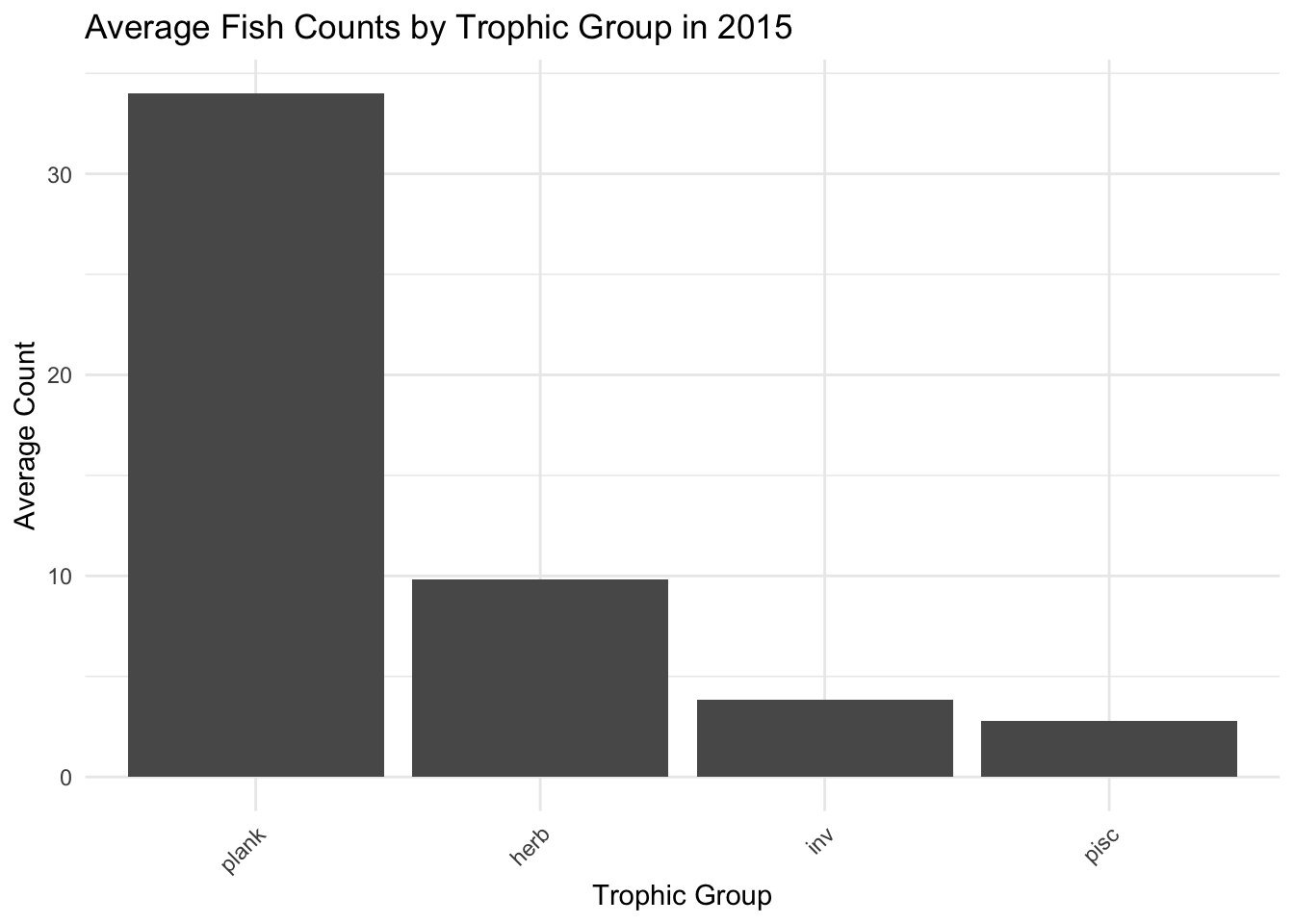
This code filters the data, calculates average counts by trophic group, and creates a bar plot of the results.
Practice Script : Lab assignment 1 in R
Copy this into your R script to run the code to complete lab assignment 1 in 18 lines of code
# load libraries library(readxl)library(dplyr)library(ggplot2)library(httr)# download excel file from github and read in as daturl<-"https://github.com/laurenkolinger/MES503data/raw/main/week1/TCRMP-RAPID-Dec2017-Health-intercept.xlsx"temp_file<-tempfile(fileext =".xlsx")GET(url, write_disk(temp_file))dat<-read_excel(temp_file, sheet ="DATA")# Create a summary of the length data for the specified specieslength_summary<-dat|>filter(SPP%in%c("AA", "OA", "OFAV", "OFRA", "PA", "SS"))|># Filter rows to include only the specified speciesgroup_by(SPP)|># Group data by speciessummarise( mean_length =mean(LENGTH), sd_length =sd(LENGTH), SEM_length =sd(LENGTH)/sqrt(length(LENGTH)))# Compute summary statistics: mean, standard deviation, and standard error of mean for lengthprint(length_summary)# Plot the average length of the specified species with error barsggplot(length_summary, aes(x=SPP,y=mean_length))+geom_bar(stat="identity")+# Create bars for mean lengthgeom_errorbar(aes(ymin =mean_length-SEM_length, ymax =mean_length+SEM_length), width =0.2)+# Add error bars xlab("species")+# Label the x-axisylab("length (cm)")+# Label the y-axisggtitle("average length of 6 common coral species ± SEM")# Add a title to the plot# Create a summary of the count and percentage of observations for each transect and speciesprev_summary<-dat|>group_by(TRANSECT, SPP)|># Group data by transect and speciessummarise(count =n())|># Compute count of observations for each groupmutate(percentage =(count/sum(count))*100)|># Compute the percentage of observations for each group relative to the total countfilter(SPP=="MC")# Filter rows to include only the species "MC"prev_summary