While the mathematics mirrors goodness-of-fit testing, independence tests calculate expected frequencies differently. Instead of using theoretical expectations, we derive expected frequencies from the observed data itself. This approach helps us understand relationships between categorical variables.
The core question in independence testing is whether two categorical variables influence each other. For example, does education level affect voting patterns? Or does genetic variation relate to disease risk? We express this formally through our null hypothesis (\(H_0\)): the proportions of one variable remain constant across different levels of the second variable.
Real-World Applications
Let’s examine two compelling examples that show how independence testing works in practice.
Safety Equipment and Injury Patterns
A study of bicycle accidents in New South Wales examined the relationship between helmet use and injury type. This straightforward 2×2 analysis carries important public health implications:
The remarkably small p-value (3×10−26) reveals a clear pattern: cyclists without helmets suffer proportionally more head injuries. The continuation correction, appropriate for 2×2 tables, ensures our conclusion is conservative and robust.
Note
In the chisq.test() function in R, the correct parameter determines whether Yates’ continuity correction is applied to the chi-squared test for a 2x2 table:
correct = TRUE: This applies Yates’ continuity correction. This correction is used to make the chi-squared test more accurate for small sample sizes, specifically for 2x2 contingency tables. It slightly reduces the chi-squared value to adjust for the fact that the test may be overly sensitive with small datasets. The correction helps reduce Type I errors (false positives) but might be conservative.
correct = FALSE: This disables the continuity correction, which means that the chi-squared test is performed in its standard form without any adjustment. This is typically used when you have a larger sample size or if you don’t need the conservative nature of the corrected test.
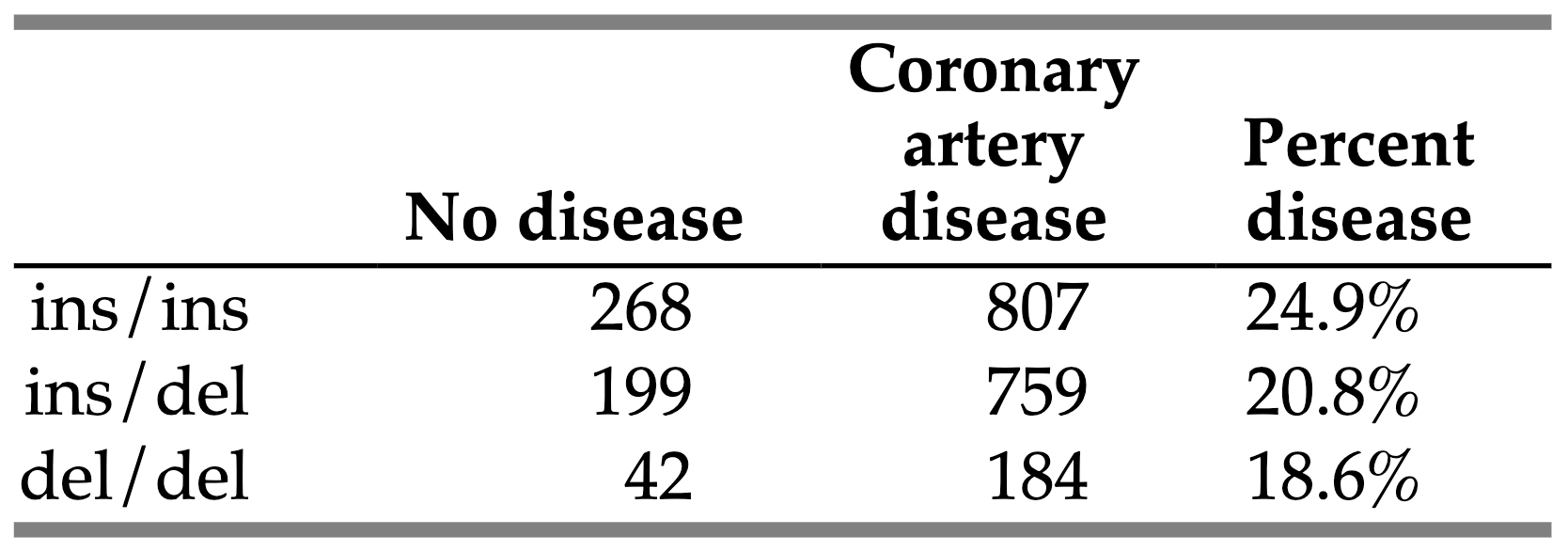
A more complex example comes from genetic epidemiology. Researchers studied how variations in the apolipoprotein B gene might influence heart disease risk. They examined three genetic variants (ins/ins, ins/del, del/del) against disease status:
Input=("Genotype Health Countins-ins no_disease 268ins-ins disease 807ins-del no_disease 199ins-del disease 759del-del no_disease 42del-del disease 184")Data.frame=read.table(textConnection(Input),header=TRUE)# Create and view the contingency tableData.xtabs=xtabs(Count~Genotype+Health, data=Data.frame)Data.xtabs
Call: xtabs(formula = Count ~ Genotype + Health, data = Data.frame)
Number of cases in table: 2259
Number of factors: 2
Test for independence of all factors:
Chisq = 7.259, df = 2, p-value = 0.02652
# Run the independence test chisq.test(Data.xtabs)
The chi-square value of 7.26 (p=0.027) suggests genetic variation does influence disease risk. Unlike our helmet example, this analysis used three categories, giving us two degrees of freedom. The relationship here is subtler but still statistically significant.
When interpreting independence tests, remember that statistical significance doesn’t always mean practical importance. Consider your sample size, study design, and real-world implications alongside the p-value. For small samples or low expected frequencies, Fisher’s Exact Test might provide a more reliable alternative.