Data Management and Organization

Why Care About Data Management
In the digital age, data has become an everyday result of scientific research. However, with the exponential growth in data volume and complexity comes an increased risk of mismanagement, potentially undermining years of painstaking work Eaker (2016) . The scientific community is grappling with a reproducibility crisis, where a significant portion of published research cannot be replicated. This crisis isn’t just a matter of academic integrity; it has substantial financial implications.
Consider this: the lack of reproducibility in scientific research, often stemming from poor data management, costs an estimated $28 billion per year in the United States alone Baker (2015) . The consequences of inadequate data management can be both immediate and far-reaching. In one notorious incident, a researcher using a homemade computer model erroneously reversed two columns of data, leading to the retraction of five published articles Miller (2006) .
Even well-intentioned efforts to preserve data can fall short without proper planning. A study found that the availability of research data declines by 17% per year, with much of this loss attributed to outdated storage media and lack of proper documentation Vines and others (2014) .
But it’s not just about preserving data; it’s about maintaining its usability and interpretability over time. Research has shown that soon after a project concludes, researchers begin to forget specific details about data collection and processing. As time progresses, even general details about the data start to fade. If a researcher changes positions or retires without leaving adequate metadata, critical information about the project could be lost forever. This is also known as information entropy Michener et al. (1997).
The message is clear: effective data management is not a luxury, but a necessity in modern research. It’s a critical component of scientific integrity, reproducibility, and the efficient use of research funding.
TLDR
- Poor data management in research can lead to irreproducibility and significant financial losses.
- Research data availability decreases by 17% per year due to outdated storage and poor documentation.
- Data usability and interpretability decline over time, especially if metadata isn’t properly maintained.
- Effective data management is crucial for preserving scientific integrity, reproducibility, and the efficient use of research funding.
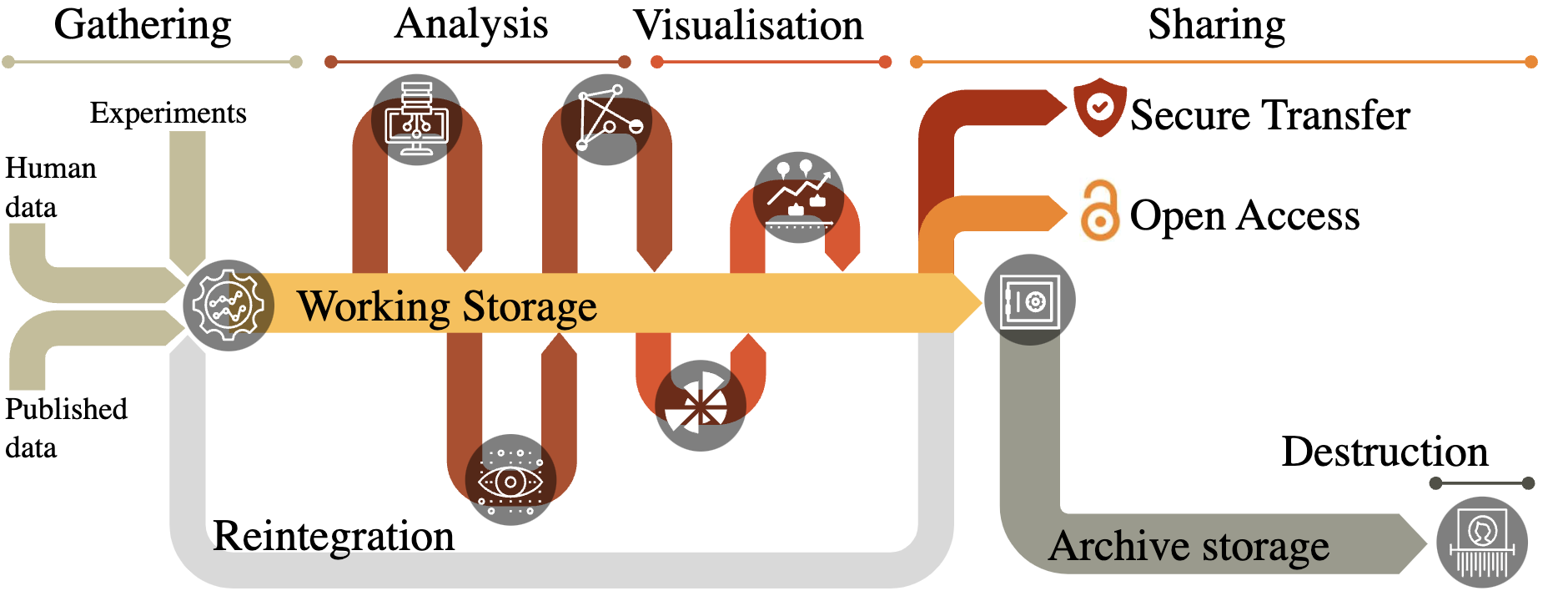
Tabular Data

The data, when organized, will be in rows and columns format. Each row is a different sample, and each column represents a different variable.
Importance of Tabular Data:
An organized view of the information within the data.
Excel and R are set up to work quickly with tabular data.
Most statistical tools prefer data in tabular form because of the structure of the data.
You’ll thank yourself later by keeping an organized version of your raw data in table form (I promise.)
Metadata
Metadata: “data about data.” It gives a description and context to your data, that makes your data understandable and interpretable.
Below are a couple of reasons why you must include metadata in your Excel workbook:
Metadata clarifies what each column in your dataset represents.
Definition of the data type, units, and other specificity ensure consistency across datasets.
In the case you may not be available to help someone understand or use your dataset, it would be helpful for the future.
Emphasizing units in metadata is very important. Whether it is meters, seconds, kilograms, or any other unit, it should be defined correctly to avoid possible misinterpretations or errors of analysis.
Your metadata must include
Name of Column: The exact name as it appears in your dataset.
Description: This is a brief description of the data represented in that column.
Type of Data: Categorical, Numerical, Date, etc.
Units: Any units that the data is measured in.
Notes: Any other notes or context regarding the data in that column.
Always Remember to:
Keep the Original: Always make a copy of your original dataset (with metadata) before starting analysis or manipulations. This will ensure that the authentic nature of your raw data will be preserved without modification.
Backup: Raw and processed data should be backed up regularly to prevent losses.
Version Control: Save versions at appropriate steps along your analysis. This way, you can see clearly how your data handling has evolved and revert to an earlier version if necessary.
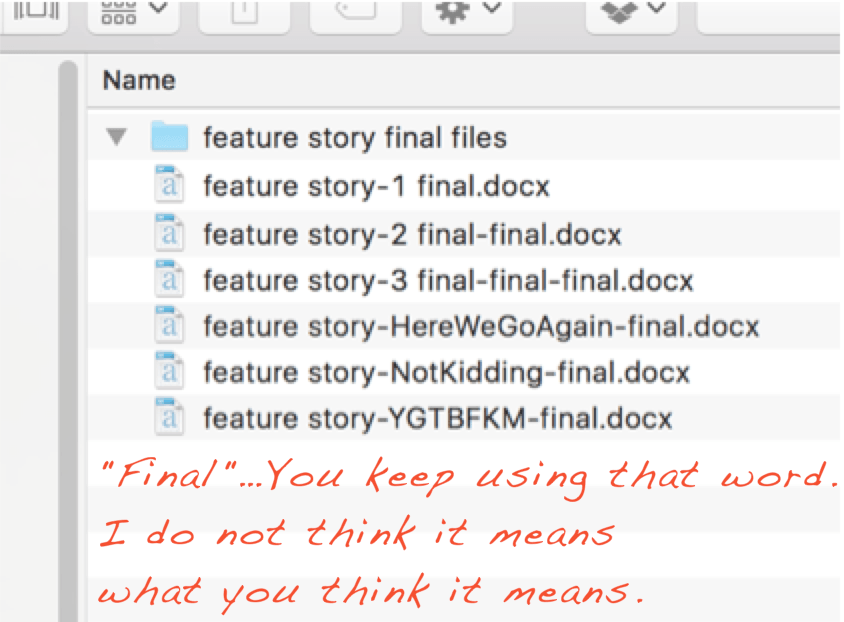
TIP: Save your derived datasheets (XLSX or R outputs) with dates at the end; for example, data_21aug2023.xlsx. Do not use words like “final” to describe your data!
Other Pearls of Wisdom for Effective Data Management
Plan Comprehensively: Before beginning any research project, develop a detailed data management plan that covers collection, processing, and preservation strategies.
Implement Rigorous Data Input Practices: Use data validation tools and input forms to reduce the chance of errors during data collection.
Document Meticulously: Stay current on documentation throughout the project. Remember, what’s obvious now may be mysterious in a few months or years.
Backup Religiously: Maintain at least three current backup copies of important work, including the original unprocessed dataset and milestone versions of processed files.
Prioritize Data Cleaning: Give adequate attention to cleaning errors from the dataset prior to analysis, but be careful to maintain legitimate outliers.
Preserve Raw Data: Always keep an unaltered copy of the raw data. This allows you to start over if needed and aids in reproducibility.
Version Control: Use version control systems or clear naming conventions to track changes to your datasets over time.
By adhering to these principles, researchers can significantly reduce the risk of data loss, enhance the reproducibility of their work, and contribute to the overall integrity of scientific research. Remember, in the world of research, your data management practices are as important as your experimental design or analytical methods. They are the unseen foundation upon which scientific progress is built.
